Listening, posture and languages
Adapted from:
A. Tomatis: Siamo tutti nati poliglotti, Edizioni Ibis, Como-Pavia, 2003
A. Tomatis: L'orecchio e la vita, Edizioni Xenia, Como-Pavia, 2017
C. Campo: L'orecchio e i suoni fonti di energia, Edizioni Riza, Milano, 1993
C. Campo: Introduzione al metodo Tomatis, Università degli Studi di Ferrara, 2002
C. Campo: Il metodo Tomatis, Edizioni Xenia, Como-Pavia, nov. 2020
Listening is a process that globally involves our organism, characterising in a specific manner even posture: this explains the psychological connections existing between the upright posture, balance and the ear. But it also involves, in some way, ethno-linguistic differentiation, anchoring language to the specific environment in which it is spoken.
For those who know Tomatis's studies, the affirmation that verticality and language go hand in hand in man is taken for granted. To clarify this aspect, however, it will be well to open a parenthesis, mentioning the phylogenetic evolution of the ear, starting from the lower animal species and ascending gradually up to man (Figure 4). The deepest and most complex part of the ear, we know, is the inner ear. It is an apparatus composed of a centre that controls balance, the vestibule, and of the cochlea, which is the instrument of the analysis of sounds and of energetic recharge. It is a kind of shell full of liquids and lined with sensory cells. A very primitive sketch of it may be observed in the hydromedusa, a very simple organism in which one may notice a lateral nerve. This nerve presents eight centres, which are eight energy stations and which function under the action of the current of water. In the course of the evolution of the species, this system, while remaining fundamentally the same, is perfected and enriched with an apparatus of orientation. In certain fish, to this lateral nerve is added the lateral tube. It is a tube that departs from the eye and that surrounds the fish. We find it on both sides of the animal. It is full of water, being furnished with openings that allow it to be in communication with the external environment. This tube functions as a generator of energy, which is distributed in the form of nervous impulses, thus allowing the fish to move. The lateral tube is dotted with openings and is accompanied by a nerve called the lateral nerve.
In order to function as a generator of energy, this lateral tube, which is full of water, is lined with sensory cells, also called ciliated cells. These are cells furnished with cilia arranged in small tufts. The water that passes in the tube makes the cilia vibrate at very high frequencies. The stimulations thus obtained are then transmitted to the lateral nerve, which in turn converts them into nervous impulses.
This same lateral tube responds also to a second function. If the agitation of the cilia generates nervous energy, the angle that these cilia form with the surface of the tube varies according to the movements of the fish. The movements of these cilia thus allow the fish to know the nature of its movements and the forces of the current. For example, it feels whether it is descending or rising towards the surface.
Along the chain of evolution, and already in certain fish, the lateral line contracts and closes up to become the otolithic vesicle. The first advantage that derives from this is that, by suppressing the whole length of the column of water, one also eliminates the factor of inertia that the latter represents.
In the same way as the lateral line, the otolithic vesicle functions exactly like the ancient lateral tube, with ciliated cells immersed in a liquid medium. In the same way as the lateral line, the otolithic vesicle is sensitive to the variations of the movements of the liquids that are now enclosed within. To increase this sensitivity, it is provided with a small calcareous mass, a kind of little stone, and every time the animal turns its head, this calcareous mass changes position and makes the liquids that surround it move, thus generating energy and measuring, in some way, its movements.
Aquatic life posed, in practice, no problem of heaviness, but from the moment the animal emerges from the water to live immersed in the air, it is necessary for it to render its apparatus more complex, so as to respond to greater energetic needs and to control, henceforth ever better, its verticality. To judge from the path followed by evolution, it seems that the vertical posture constitutes, for the moment, the most economical stage from the point of view of the expenditure of vital energy and the most
profitable in terms of energetic production. In the serpent, the otolithic vesicle becomes more complex and divides into a saccule, which has the task of controlling verticality, and a utricle, which ensures the horizontality of the animal. To the utricle is added a sketch of semicircular canals, whose role will be to control the rotatory movements. Even if the apparatus becomes more complex, its function remains essentially the same, that is, to generate energy and to control movements.
The materials used have not changed; they are ciliated cells that move in a liquid. When, in certain animals, there appears a new part called the lagena, one may observe that some of these animals raise their head appreciably. The lagena is developed to the maximum in birds, in which one finds a sketch of a middle ear.
The lagena will be succeeded by the cochlea, whose presence determines verticality. It is also the specific instrument of the analysis of sounds.
It is these various elements that form, in man, the labyrinth, that is, the inner ear. It is a generator of energy and, at the same time, makes it possible to control all the movements of the body. Naturally, the ear alone would serve no purpose. It is enclosed in a shell that has moulded it, called the bony labyrinth; from it emerge nerves that depart from the utricle, from the saccule, from each of the semicircular canals, to constitute what is called the vestibular nerve, which at a certain point has a ganglion and continues until it forms the vestibular nuclei. These are four in number and function exactly like a primitive brain. Thanks to the nerves that depart from the vestibular nuclei, all the muscles of the body are reached, none excepted.
Every time one is obliged to assume any posture or position of balance, thanks to the intervention of the two labyrinths, an information is sent to the muscles to that end. Each muscle sends back the information to give notice of the position and of its state. This returns to an intermediate relay found in the cerebellum, connected to the vestibule by means of the vestibular nuclei. All the muscular movements therefore pass through the labyrinth.
Let us close this phylogenetic and anatomo-physiological parenthesis and, in the light of what has been said, let us try to show the connection between language and posture. In order to make the best use of the thousands of ciliated cells of the inner ear, the vestibule and the cochlea must be oriented in space in such a way that the utricle is in a horizontal position and the saccule in a vertical position; it is this position that gives the greatest number of stimulations at the level of the cells. It is in this position that one has the greatest cerebral stimulation. And it is the head that, positioning itself correctly, places the labyrinth disposed according to these axes, and the good posture of the head depends upon a good distribution of the tensional forces that maintain the body upright. This verticality, in turn, is actuated by means of the vestibule-cerebellum-muscular system circuit.
An ear, then, that manages to listen well — and above all to the high sounds — favours, through vestibular cybernetics, a good verticality. Language, which fastens onto the very fine capacity, acquired by the human ear, to analyse the small tonal differences corresponding to the various sounds contained in the language, requires a good listening and a good verticality.
If one tries, indeed, to speak while on all fours, and if one continues the discourse for a long time in this unusual position, a discomfort begins to make itself felt, which is not at all linked to the apparent inconvenience of the situation, but to the difficulty of setting oneself to listen. For Tomatis, indeed, to strain the ear is also to strain the whole body to listening, and to do this it is necessary to offer to the information the most sensitive parts of the person. The anterior part of the dermal-bodily epithelium is the richest in sensory fibres capable of capturing, to a certain extent, the sensations corresponding to pressures. This sensory network also manages to transmit the information to the skeletal system, thus adding a bone transmission to the informational stimulations. From this moment, listening improves and transforms the postural attitude, while the latter in turn allows listening to perfect itself, thanks to the message that begins to arrive in a more faithful manner. The cochlear and bodily actions, reactions and counter-reactions hold in their mechanism the most important keys of verticality. These evolve in parallel with language, which is, for Tomatis, none other than the biological translation of the act of listening. Indeed, everything gives a glimpse that there exists first a dull dialogue in the depths of the linguistic structure, followed by a familiar language made of conditionings responding to immediate necessities; to this succeeds the socio-cultural linguality, which ought to be the affirmation of the function of hearing and permits, to a certain extent, access to the comprehension of teaching, of which it is the vector. Finally, in an ultimate stage, there appears the reflexive language produced by a profound listening, beginning a dialogue with thought itself, until the obtaining of a verbalised secretion that is none other than thought in its substance, or the "incarnate logos", to paraphrase Tomatis.
Language and bodily image
The intimate correlation between the ear and the global bodily image passes through their point of junction: language. This is the fruit of listening and demands, in order to be controlled, affirmed, conducted into its smallest modulations, that the ear be open, and that it be so to the point of listening. Which is no small thing, inasmuch as it (listening) introduces the conscious field into a real dimension.
In order to organise this particularly delicate device, the ear guides — not to say imposes — a whole bodily assembly at the level of its mental representation, the reflection of the cortical image. Thus the person who comes to acquire an ideally expressed language — and it is already much that one can accede to it — ends by installing himself in a postural attitude that responds to an ideal attitude, which he who speaks following norms judged excellent may reach. The phenomenon is even clearer in singers and actors who find themselves, for professional reasons, put in the condition of having to acquire a perfect emission regarding sounds that they must know how to control strongly. Postures are very revealing and make it possible to understand, in this case, the necessity of a well-defined scenic bearing in view of the realisation of an act that demands a perfection of execution. With the Electronic Ear, the apparatus invented by Tomatis to re-educate listening, it is easy to see postural changes according to the auditory modifications introduced. Indeed, by imposing, thanks to electronic gates, a hearing rich in high frequencies, one observes, the moment phonation comes alive, a notable postural correlation. One notices above all a straightening of the spinal column and an appreciable opening of the thoracic cage; alongside this, one also observes the search for a better dorsal rectitude through a rotation of the pelvis by anteversion of the pubic part. At the same time, the face relaxes and mobilises itself in a harmonious manner, not tense, while the voice lights up. It is very difficult to observe, for example in class, a child who follows the lessons attentively while sprawled on his chair. And it would be complicated to set in motion the mechanism of listening while maintaining such a posture. Moreover, the one who speaks has the sensation of being listened to when his interlocutor holds himself in an upright posture, and not when he shows himself as slumped upon himself.
Tomatis proposes an exercise to understand what the listening posture is. He calls it audiogenic training. One may assume it starting from a seated position on a stool adjusted in height so as to have the knees slightly lower than the pelvis, in order to favour the good positioning of the latter. With the eyes closed, the head seeks its point of balance so as to favour an optimal perception of the high tones present in the environment. It will then be a matter of mobilising adequately the musculature of the middle ear. One begins by imagining that the whole scalp gathers itself in the upper part of the head, the vertex, which corresponds to the point of the tonsure of monks. This done, the folds that furrow the forehead horizontally begin to disappear. If all goes well, one has a clear sensation at the roots of the hair, with a perception of freshness in this part of the skull.
This operation having succeeded, one will now imagine broadening the forehead, as much as if the skin wished to touch the walls of the room in which we find ourselves. Immediately afterwards we bring this skin to gather at the same point where we made a chignon with the scalp. Drawing it tight, so that the skin tenses itself. At this point, if the operations have been carried out well and the head has been maintained in its position indicated at the beginning, the vertical wrinkles of the forehead, if there are any, begin to smooth out, and certain vasomotor modifications begin to occur: the face turns red and warms up, then loses colour while the respiration becomes broader and deeper, more relaxed: it really tends to unblock itself, to become what it should normally be.
The eyelids, held until this moment voluntarily lowered, close under the effect of their weight, accompanied by a trembling in their external part. At this point, still imagining, we take the skin of the face beneath the forehead and broaden it until it too touches the walls of the room. This done, we bring this part of skin too to gather in the small chignon situated at the vertex of the head. To this will be added the two ears, which will come to be situated on the summit of the skull.
The action at the level of the skin will be evident. One will have the sensation that a thin layer of rubber has been applied to the face, so much is the action felt in the facial muscles. It is like a "physiological lifting" that comes to act upon them. Moreover, in the meantime, the upper lip is left to rest upon the lower lip as upon a capital. There will thus be established a balance between the orbicular muscles of the lips and those that act upon their commissures, while the lower jaw maintains contact with the upper without contractions. At this point the face begins to assume a very relaxed and rested expression, as if it were free from the marks that worries leave upon the skin. This stage reached (very pleasant, to tell the truth, and such that whoever experiences it would wish to maintain it for ever), while conserving the facial quiet, one seeks to perceive the surrounding environment. At this point one realises that something changes. The noises begin to purify themselves, they assume a clearer timbre. The low sounds are attenuated, while the component of high sounds present in them increases. Everything seems to become more luminous and alive.
If one tries to listen to one's own voice in these conditions, one has the sensation of perceiving it for the first time, more rounded and rich in harmonics. One has, moreover, the sensation that it is the right ear that directs the listening and that draws the left ear to a point localised at the vertex of the head, precisely where we gathered the small chignon. Physiologically this is called the point of fusion.
The ideal would be that one managed, from that moment, to perceive one's own voice as if it were anchored at that point. This manner of perceiving sounds and one's own voice has a correlate, if we may so say, that is psychological, which is the possibility of objectifying better the relationships with oneself and with others.
It is this listening posture that good singers assume unconsciously at the kindling of their own voice. It is the posture of free, deliberate, unconstrained listening, where the person can listen to himself and listen without interferences coming from the "limbic" depths of consciousness.
Sound sculpts the body
Language therefore directs the posture of the subject towards a certain direction. The better the quality of language — that is, of listening, the former depending upon the latter — the better the postural attitude. We can imagine the body subjected to the modelling work of sound, thinking that it is surrounded by stimuli and impulsions that continually excite all its points. The sum of these pressures ends by composing an integrated image of the body. It is very easy to feel this by immersing oneself in a surface of agitated water. At the touch of the waves one perceives better the limit of the body.
Naturally there exist privileged zones that are touched more sensibly by sound and by language, such as the face, the anterior face of the chest and of the belly, the dorsal face of the right hand between thumb and index, the inner part of the lower limbs, above all at the level of the knee, the soles of the feet. These are zones of the bodily surface with the greatest density of nerve fibres specialised in perceiving pressure stimuli. It thus becomes clearer that verticality is necessary in order to offer the greatest possible surface to the sonic stimuli, if one wishes to develop language. According to Tomatis, the vertical posture would not, after all, be the best in absolute terms to this end, but there would exist another, of oriental origin, namely the lotus asana in the discipline of Yoga, which (a coincidence?) permits a better exposure of the bodily zones described above to the acoustic stimuli.
It is interesting to point out that one's own bodily image may be imposed upon the other, more or less consciously. In this regard Tomatis recounts an experience of his in South Africa, with a stuttering subject. An extremely brilliant person, afflicted with a very strong stutter that was accompanied by uncoordinated movements. In a short time, during the consultation, which other people were attending, everyone was moving like him, with the same gestures. The most surprised was the interpreter, who was the most involved in the language of this subject. His image of the body was so strong that, in the course of the consultation, he had imposed it upon everyone. This happens when the personality is strong. In the same way, a good singer euphorises us: in a short time it is as if we ourselves were singing; the breath expands, the face relaxes. In the presence of mediocre singers, one comes to suffer, inasmuch as one tends to do as they do, one pushes on the larynx, tightening the throat. According to these perspectives, a dialogue occurs when two people set each other into vibration. According to Tomatis, what we desire to transmit originally are not the manners, nor sounds, but sensations profoundly felt, profoundly lived within us by our sensory neurons. What we desire to communicate are the tactile impressions that speech makes run over our sensory keyboard. Without knowing it, we transmit the same chords to our interlocutor, who unconsciously makes his own keyboard function in the image of ours, so that we shall enter into resonance.
An experimental verification of the compatibility of bodily images may be made by imposing upon two subjects identical auditory curves and launching them into a thorny discussion: very rarely will they fall into disagreement. Afterwards one inverts the curves and begins a very banal dialogue: it is very easy that, within a few minutes, the two people are quarrelling. This shows to what extent the mental is influenced by the body, and how much the latter in turn modifies the language by which it is sculpted. The mind-body interaction is therefore reciprocal. Which of the two parts is at the origin of the process of interaction is difficult to say.
Ethno-linguistic posture
Another very important factor that influences the bodily image is what Tomatis calls the acoustic impedance of the medium. The acoustic impedance of the medium is the name given to the set of minimal resistances that the environment offers to the propagation of sound. Every medium through which sound travels offers a certain resistance to the sound itself, favouring or not its passage, accentuating or diminishing its intensity at certain frequencies. Now, air is the principal medium through which sound is transmitted. The voice, the sound of an instrument, a noise, before reaching the ear of the receiver, crosses a layer of air more or less large in relation to the distance between sender and receiver. The air, however, is not the same in all parts of the world, nor even within one and the same country. Numerous geographical, climatic and environmental factors influence the consistency of the air in a different manner, at different points of the earth's surface. Tomatis travelled the world for a long time with a very simple apparatus, consisting of a microphone connected to a recorder and a loudspeaker apt to emit identical sounds at a determined distance. By analysing the same sounds emitted by the loudspeaker in different geographical zones — thanks to panoramic analysers that decompose sounds into their various frequency components — it emerged evidently that the same sound, depending upon the geographical place where it was recorded, was richer in certain frequencies than in others; it could, that is, in a certain place, be richer in high frequencies, in another in low frequencies, and so on. In the space intervening between the loudspeaker and the microphone, the only thing to change from one place to another was the air. As proof of this, Tomatis analysed a vast sample of voices of people from the same places where he had recorded the sound emitted by the loudspeaker. The correspondence of the frequencies was astonishing; one could determine linguistic zones that had nothing in common with the socio-geographical frontiers. It was possible to construct a fairly detailed acoustic geography of various geographical zones. Immersed in a particular acoustic bath, the ear begins to privilege the frequencies best perceived in that zone, and in consequence comes to influence phonation. Certainly the hereditary, cultural and sociological factors are to be taken into consideration, but the influence of the acoustic criteria remains considerable.
Some centuries ago, the English emigrant installed himself on the American continent, where the air vibrates more at 1500 hertz, a frequency that he can hear but that provokes in him sensations different from those to which he is accustomed.
Little by little his perception changed, and with it his whole deep system of auditory responses and of neuronal counter-reactions. He acquired another posture, another attitude, specific to the new ethnicity. He modified his behaviour, adopted an unusual psychological approach. These new conditions obliged the body to adapt in relation to the new acoustic universe. The tension of the eardrum is no longer the same. The nervous system, in order to be in accord with the cochlea, is constrained to modify its functioning. In turn, a part of the middle ear — in particular the muscle of the stirrup — must change its mode of operation. This being under the control of the facial nerve, the muscles of the face are submitted to an unusual gymnastics. The muscle of the hammer, which is innervated by the same nerve that commands the jaw, also chooses positions suited to this new operativity. The features consequently undergo a slow, but inexorable, physiological lifting.
The parameters of languages
Following the analyses cited above and other studies on language, Tomatis comes to identify four parameters that make it possible to understand better the fantastic world of living languages. These four criteria, which we may define as the characteristics of a language, are: the "passband", the "envelope curve" within the passband, the "latency time" and the "preparation time" of the middle ear, or "precession".
The passband
Human hearing develops over a sound spectrum that goes from the low sounds to the high sounds, distributing itself from 16 Hertz up to about 16,000-20,000 Hertz. Nevertheless, in this wide spectrum of 11 octaves, the frequencies are not all perceived in the same way. There exist in every language preferential zones, or passbands, within which the sounds are perceived with greater clarity. The cause of this is the acoustic impedance of places and of environments. We know that one speaks with a completely different timbre depending on whether one finds oneself in a reverberant room or in a dead room.
On the American continent — says Tomatis — the inhabitants do not nasalise for pleasure. The ancient English or Dutch emigrants had certainly not become enamoured of the Amerindian languages, characterised by this phonetic particularity. It is not the American language that makes one nasalise. It is "the air of the place", acoustically richer between 1000 and 2000 Hertz, that obliges the ear to adopt the passband specific to nasalisation. In parallel, the French language, which uses preferentially the frequencies between 1000 and 2000 Hertz with a zone of maximum sensitivity at 1500 Hz, also presents nasalisation in its phonetics.
The envelope curve
Through the study of the spoken chain by means of panoramic analysers and sonographs — apparatus capable of decomposing sounds just as the prism manages to decompose light into the colours that compose it — it was possible to visualise the various frequencies, respecting quantitatively the relative values of each of them, and identifying the various parts of a phrase, in frequency, in intensity and in duration. On the phonograms and sonograms thus obtained, it was possible to find the envelope curves of the average values of the frequencies encountered in the course of the analysis of the phrases gathered within the same ethnic group.
A few examples with the principal European languages may clarify this concept. The diagrams of these curves were called by Tomatis ethnograms, and show, for each ethno-linguistic group, the frequency zones of greatest auditory sensitivity. On the abscissa are indicated the frequencies, on the ordinate are indicated the intensities.
The latency time
To open a door, to grasp something, to scratch oneself…, presupposes a previsional state, a preparation time, called latency. When one decides to look at something, one prepares the vision, one focuses on the object. Before joining the images of the two eyes, before focusing perfectly, a latency time has been established.
In the case of the ear, it is a matter of the time necessary to set oneself to listen. From one part of the globe to another, we do not strain the ear in the same way. This phenomenon, called by Tomatis the "latency time" or "delay", varies according to the geographical zones but also according to age. Many children irritate their parents when they oblige them to repeat the same phrase two or three times. Their ear has not yet reached the rhythm of linguistic recognition of adults. They have a latency time longer than ours. Advertisers know this phenomenon well. In their advertising plans they take account of the number of posters stuck on the walls, or of the frequency of the spots broadcast on television. They know that their impact differs according to these parameters.
When one begins to speak and prepares to listen to oneself — each of us being the first listener of his own discourse — one introduces, between us and our language, a dimension, a preparation perfectly measurable and that plays upon the verbal flow and the accentuation. The latency time is significant in songs, in folkloric chants, in the ways of telling stories. These products of tradition, indeed, bring us the pre-linguistic rhythm of the language onto which the semantics comes to fasten. Tomatis says that, for most of our contemporaries, the fact that listening depends upon a posture of the body seems an incomprehensible thing. One forgets, however, that the ear is not content to decipher sounds as the reading head of a tape recorder would do. It has at its disposal an apparatus, the vestibule, which induces the subject to put his body in a determined position in order to be able to respond. The vestibule is the seat of balance, but upon it depend equally the tone of the muscles, their relative strength and, above all, the consciousness of the bodily image. A long latency time, like the Slavic, reinforces the bodily image. It also permits a more accurate analysis of sounds, thanks to the lengthening of the time of setting to work.
Perhaps it is not by chance that many specialists of phonetics are of Slavic origin.
Tomatis came to measure the latency times of many languages and was able to observe how important this element is as a criterion of differentiation between them.
Today we know, for example, that English and Spanish share the record of linguistic rapidity with 5 milliseconds. This performance is easy for the Spanish, who speak very close to the fundamental laryngeal sounds. For the English it becomes a tour de force, on account of the high passband that constrains them to speak with the tip of the tongue, at more than 15 centimetres from the larynx.
The precession time
The last parameter to be taken into consideration in Tomatis's psycholinguistic research concerns a process of audio-bodily integration called "precession time". It is, in effect, the precession that bone conduction manifests with respect to air conduction, and corresponds to the time necessary for the middle ear to tune the tympanic tension to the sound already perceived by the bone pathway. It varies from one language to another, and upon it depends the different manner of reacting to the various linguistic registers, leading the body to adopt different postures so as to tune itself better to them.
Acoustic geography
The French language
In the case of French, one may note that the frequency zones of greatest use are situated, one between 100 and 300 Hertz, therefore in the low sounds, and another towards the high sounds, between 1000 and 2000 Hz, with a point of greatest sensitivity at 1500 Hz. The difference of sonic intensity between these two zones is about 20 decibels. The peak at 1500 Hz, with the relative fall towards the high sounds, explains the appearance of nasalisation in this language. This passband, united with a latency time of 50 milliseconds, makes French a hypervocalic language with a weak tonic accent. To give an example: a French person pronounces the word "Bonjour" in the French manner. We will hear a linear sliding made, in a first part, of a small "b" and a large "ON", and, in a second part, of a small "j" and a large "OUR". On the contrary, if it is an American native speaker who pronounces the same word, we will have a hyperconsonantal pronunciation typical of American: a Bon-Jour with a large "B", a small "on", a large "J" and a small "our". French, moreover, uses the frequency zone typical of language. This might, perhaps, explain in part the importance that language itself holds in French culture.
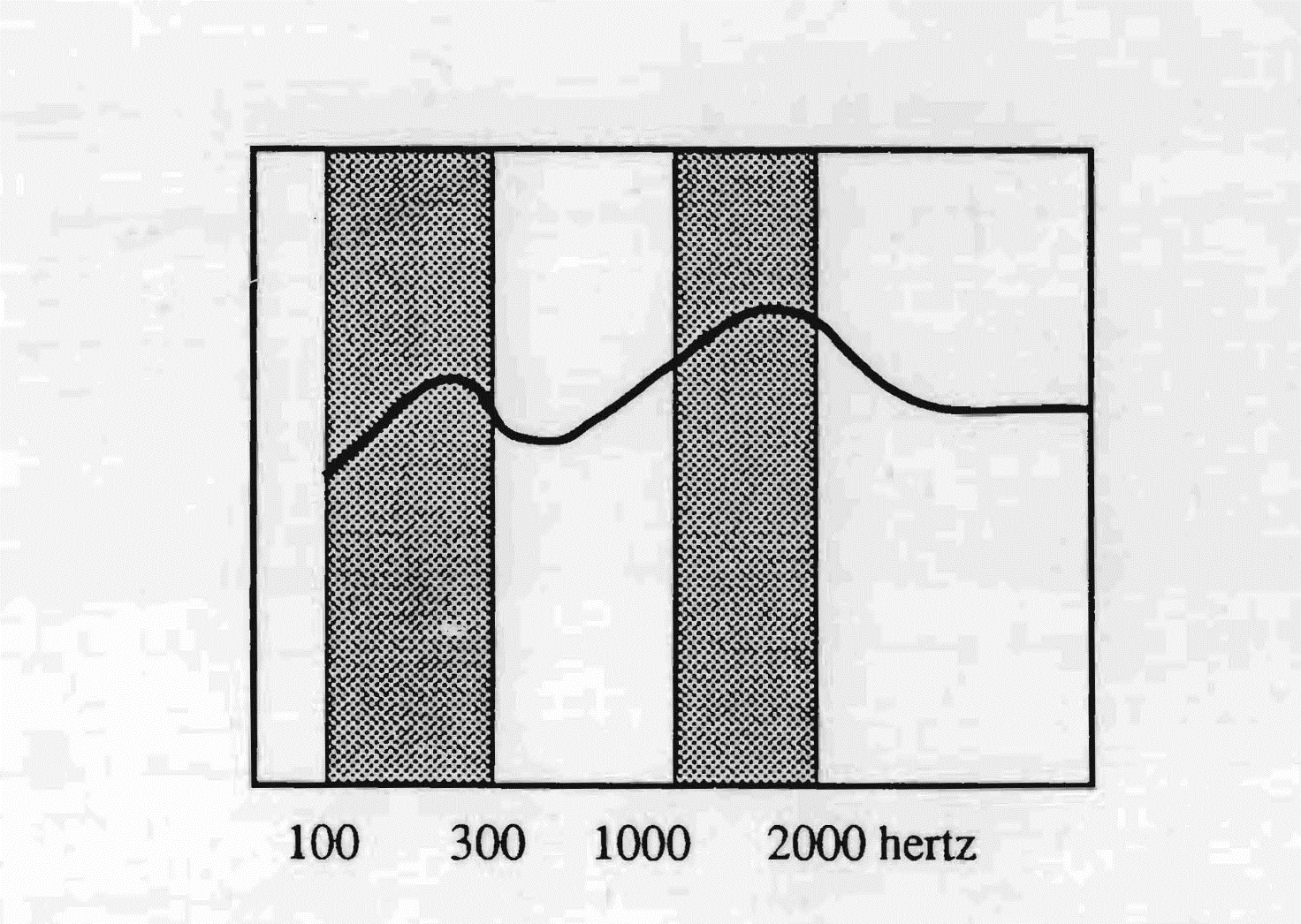
The French language uses frequencies that range from 100 to 300 hertz and from 1000 to 2000 hertz
The English language
The essential characteristic of the English type of hearing is represented by the great sensitivity to high sounds and a very rapid latency time, which come to bear, the second upon the time of syllabic emission and the first upon the bodily image, concentrated on the upper part of the body.
It is naturally a matter of the English language spoken in England. From 2000 Hz the curve traces a progression of the order of 6 decibels per octave, which is prolonged up to 12,000 Hertz and even beyond, which
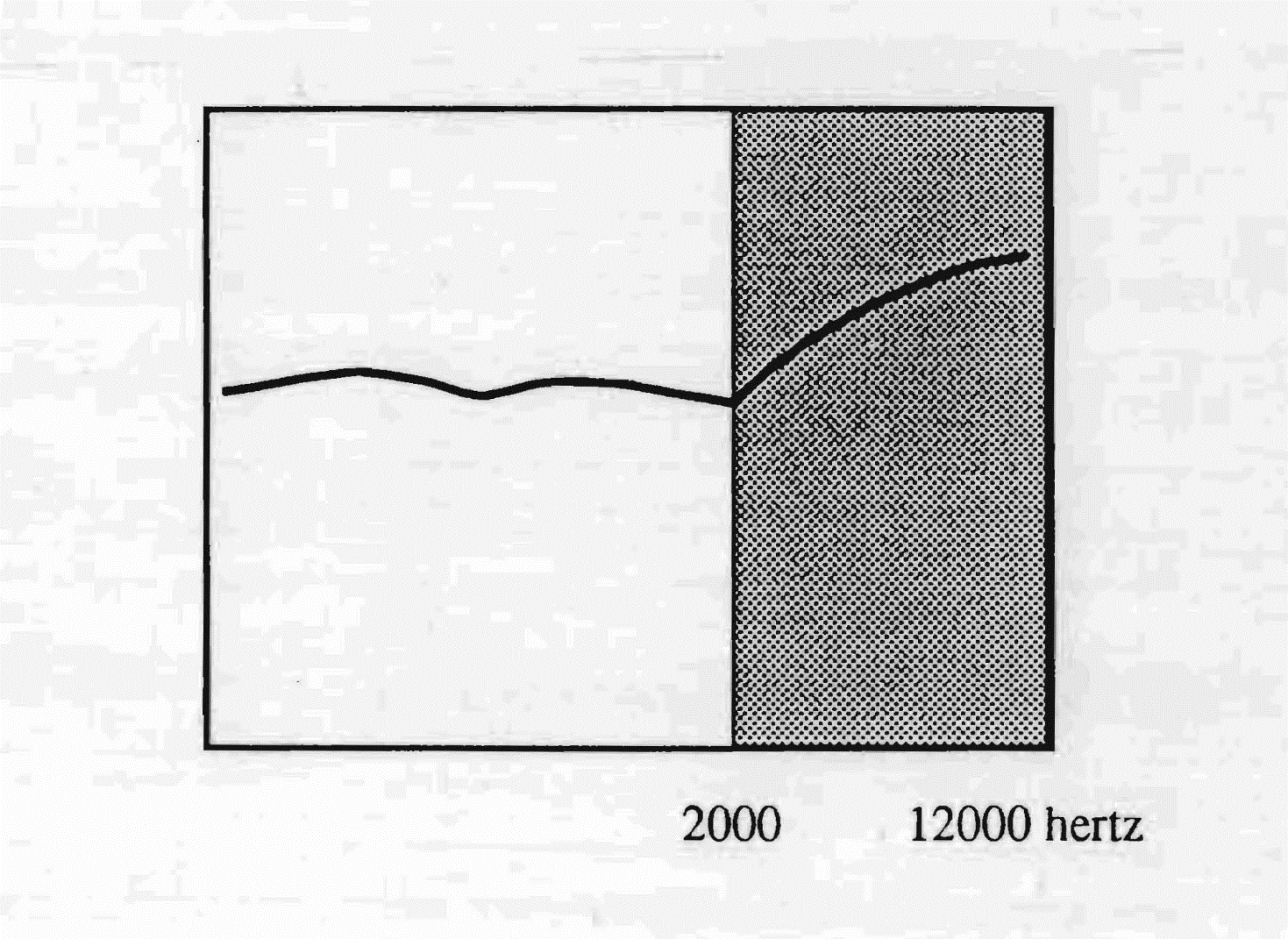
The English language uses frequencies that range from 2000 to 12,000
hertz, with a greater sensitivity in the very high frequencies
confers upon this type of hearing a response curve that recalls that of the high-fidelity amplification circuits. The consequence of this is the richness of sibilants in this language.
In the verbal flow of the English type, the attraction towards the high sounds of the whole vocalic scheme, by auditory counter-reaction, explains the systematic diphthongisation of the vowels. These, although they exist in the initial spectrum, slide from the fundamental sound towards the band of frequency situated after 2000 Hz. Indeed, the high passband perceived by the English ear imposes, by audio-vocal counter-reaction, a structure such that the fundamental sound, which is found in the low sounds on account of the limited possibilities of the larynx (300 Hertz), cannot be maintained in the initial emission, not being selected by the ear. Consequently one witnesses, in fact, a slide into the high sounds, which comes to produce the diphthongisation. It is worth pointing out that the distance existing between the fundamental sound — initially the same in all languages and always low — and the passband of a language, explains the difference, more or less great, between the written reproduction of a language and its pronunciation. This modification is the greater the more important the difference. For example, Spanish, fixed principally on the low sounds, is written practically as it is pronounced, while English presents a maximum of distortion between the spoken language and its written reproduction. Comparing the English auditory band with the French, one notes that the one uses frequencies not selected by the other ear, and vice versa. It is well known that, for the French ear, it is difficult to perceive English, and vice versa. The American language, which uses a passband lower than British English, with a point of greatest sensitivity at 1500 Hertz, is perceived better by the French ear than Oxford English.
The German language
The passband of the German language starts from the low sounds, extending up to 3000 Hertz. The sensitivity is more accentuated between 250 and 2000 Hertz, with a point of greatest permeability around 800 Hertz. The width of this passband makes it possible to integrate with ease the phonemes belonging to other languages, on condition that they insert themselves within its frequency territory.
To this wide passband is added a very important characteristic of the German ear: a relatively long latency time. This implies a strong thrust of the larynx and a notable bodily involvement during phonation, necessary to sustain the laryngeal thrust, characteristics of this linguistic group.
It is important to note that, in order to listen to and to speak a particular language, one must put oneself in the attitude imposed by it. It is the acoustic parameters — passband, envelope curve, latency and precession — that impose the posture and the motor attitude, thanks to the constant dialogue between cochlea and vestibule. For example, in order to listen to and to speak German, one must hold oneself particularly upright, have the chest well open and be well planted on one's legs. A bodily attitude that has little to do with that of an Englishman or a Spaniard.
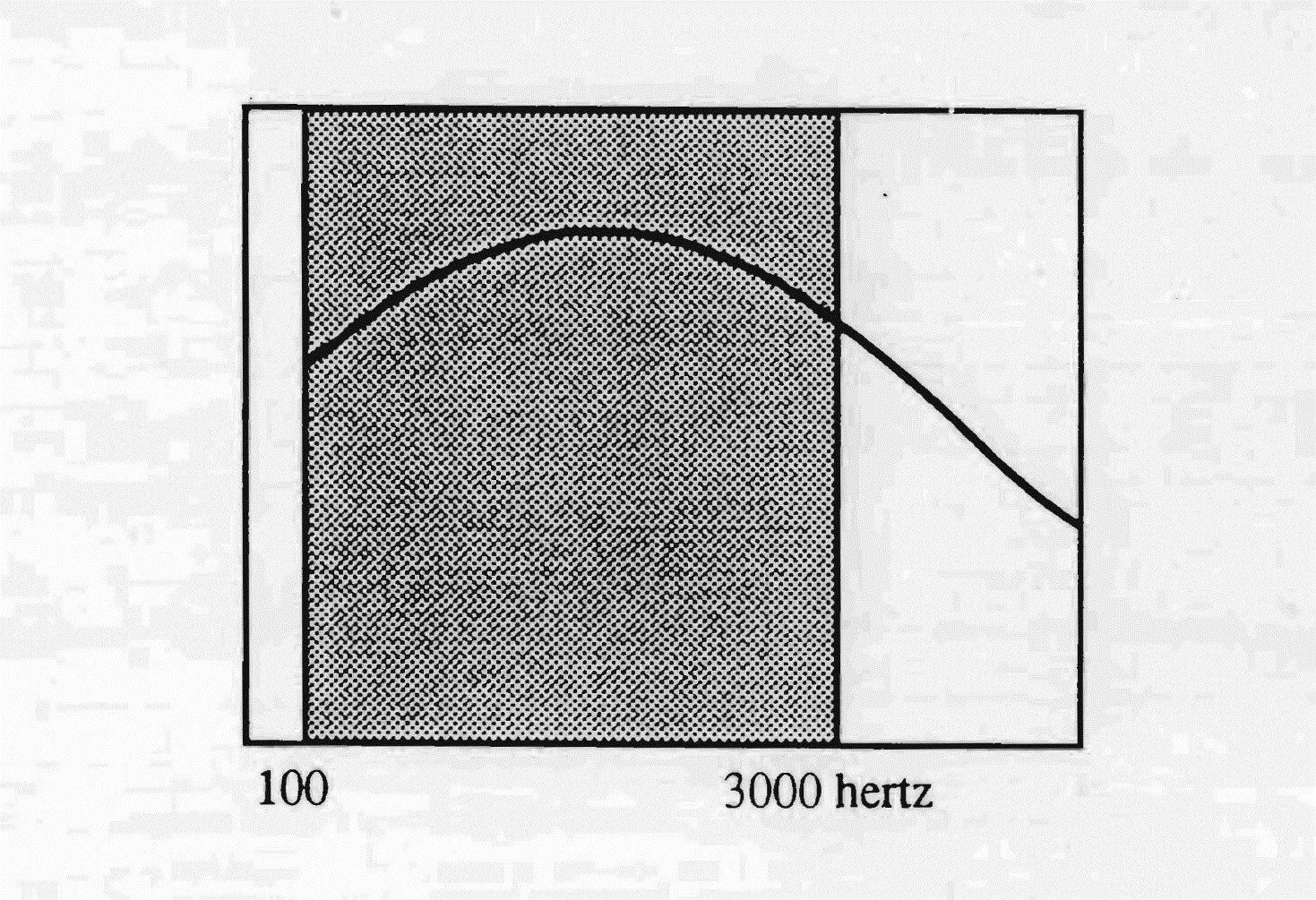
The German language uses frequencies that range from 100 to 3000
hertz, with a greater sensitivity around 750 hertz
The Spanish language
Characteristic of the Spanish type of ear is a great sensitivity to the low sounds, on a band that goes up to 500 Hertz, and a less elevated level of intensity in another zone that goes from 1500 to 2500 Hertz, with a very reduced sensitivity in the high sounds.
The point at 250 Hertz introduces, into the audio-vocal reaction, the jota, while the absence of permeability in the high sounds after 2500 Hertz explains the heaviness of the Spanish sibilants: the sliding, for example, of the "f" into an aspirated "h". It is evident, from the reading of the graph, the difficulty that, on average, a Spaniard encounters in integrating foreign languages. The preponderant use of low frequencies in the Castilian language favours a bodily image that invests much the pelvis and the legs.
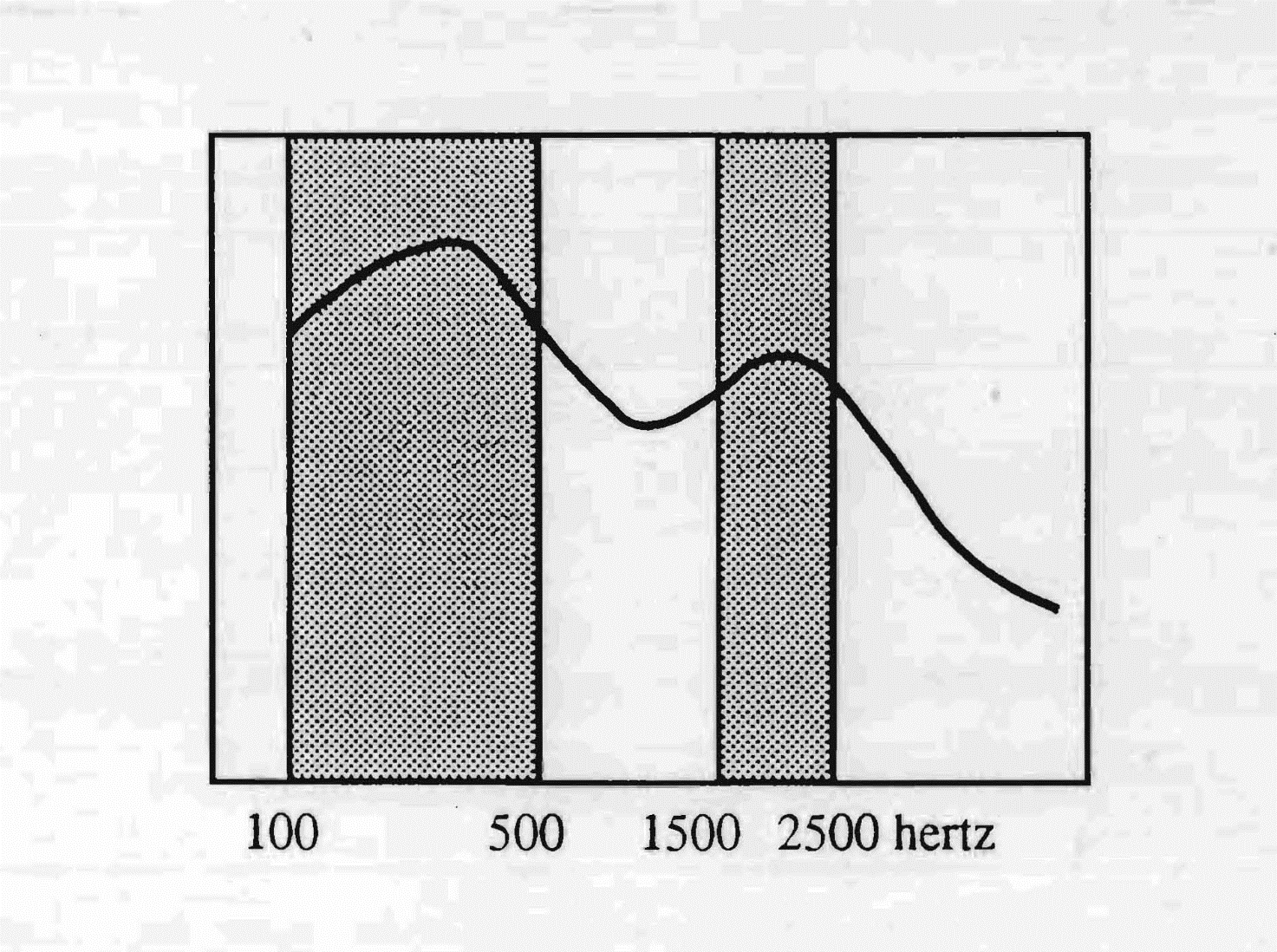
The passband of Castilian Spanish goes from 100 to 500 Hz and from 1500 to 2500 Hz.
The Spanish type of ear is more sensitive to the low sounds, where the voice is stronger. The poor
sensitivity to the high sounds explains the absence of sibilants in this language
The Arabic language
The Arabic language, on the other hand, is characterised by a passband very close to that of Castilian Spanish and a latency time of the German type. Hence the absence of sibilants, as in the Spanish language, and a strong laryngeal thrust typical of the speakers of the German language.
The Slavic languages
The Russians and the Slavs in general have at their disposal a very extensive opening of the auditory diaphragm, going from the low sounds up to the highest, with a greater affinity towards the low tones. This selective richness, contrary to that of the French, permits an excellent perception of the phonemes of other languages.
The audio-postural reflex of the Slavic type of linguistic group is characterised by the manner of holding oneself well planted on the ground, by the amplitude of the respiration, by its manner of emitting broad and warm sounds, the sign of a strong bodily integration. This depends both upon the wide passband and upon the latency time of perception, long enough to favour a strong taking on of the sound by the body.
It is interesting to point out that every ethno-linguistic group has the posture of its language, a consequence of its manner of listening.
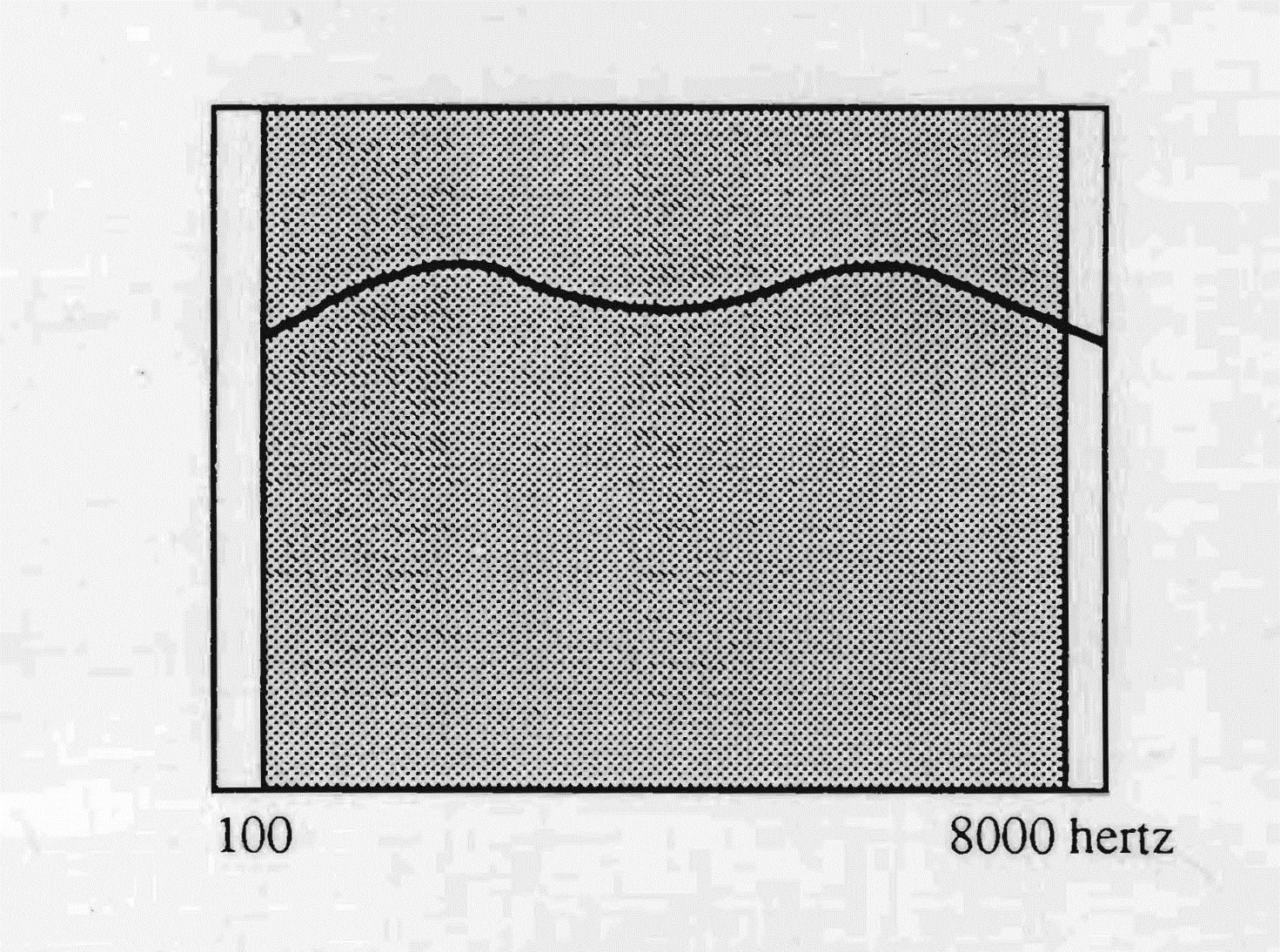
The passbands of the Slavic languages cover almost all the frequencies used by the human ear.
Hence the ease of their speakers in learning other languages easily


The Portuguese language
The Portuguese language, the one spoken in Portugal, has the characteristics of the Slavic languages (passband, delay and precession). It resounds like a Spanish self-controlled by a Slavic type of ear. Experimentally it is amusing to verify this fact by passing a Portuguese phrase through filters whose response curve is that of the Spanish ear. For those who understand Spanish, Portuguese becomes in this way more easily comprehensible.
The Italian language
The envelope curve of the Italian language, together with the particular frequency zone covered by its passband, and with the latency times proper to it, indicates a very musical ear.
The passband, though not very extensive, from 2000 to 4000 Hz, touches a frequency zone very favourable to singing. Speaking of Italian, it is often said that it is a musical language. It is not by chance that operatic singing was born precisely here. Between 2000 and 4000 Hz, the bony structure has the greatest resonance, and the bone sound is that which an operatic singer emits when he sings qualitatively well.
It is the larynx, indeed, that, vibrating against the cervical vertebrae, makes the whole skeletal structure — very sensitive to the high sounds — enter into resonance, producing the sound typical of the Italian manner of singing. The whole favoured by the audio-postural reaction linked to the Italian type of listening.
The musicality of the listening, and therefore of the phonation, of the Italian type is favoured also by the ascent of the envelope curve, which rises from the low sounds towards the high sounds with a slope of about 6 decibels per octave up to 3000-4000 Hertz, then to bend slightly towards the highest extremes.
For Tomatis this type of curve is very close to that which he calls the ideal musical listening. The latency times (75 milliseconds) and preparation times (150 milliseconds) typical of the Italian language influence the time of syllabic emission and favour the pronunciation of consonants and vowels in juxtaposition, giving the language its exquisitely musical rhythm. The "luminosity" of the sounds of the language comes from its passband, situated in the zone of melody.
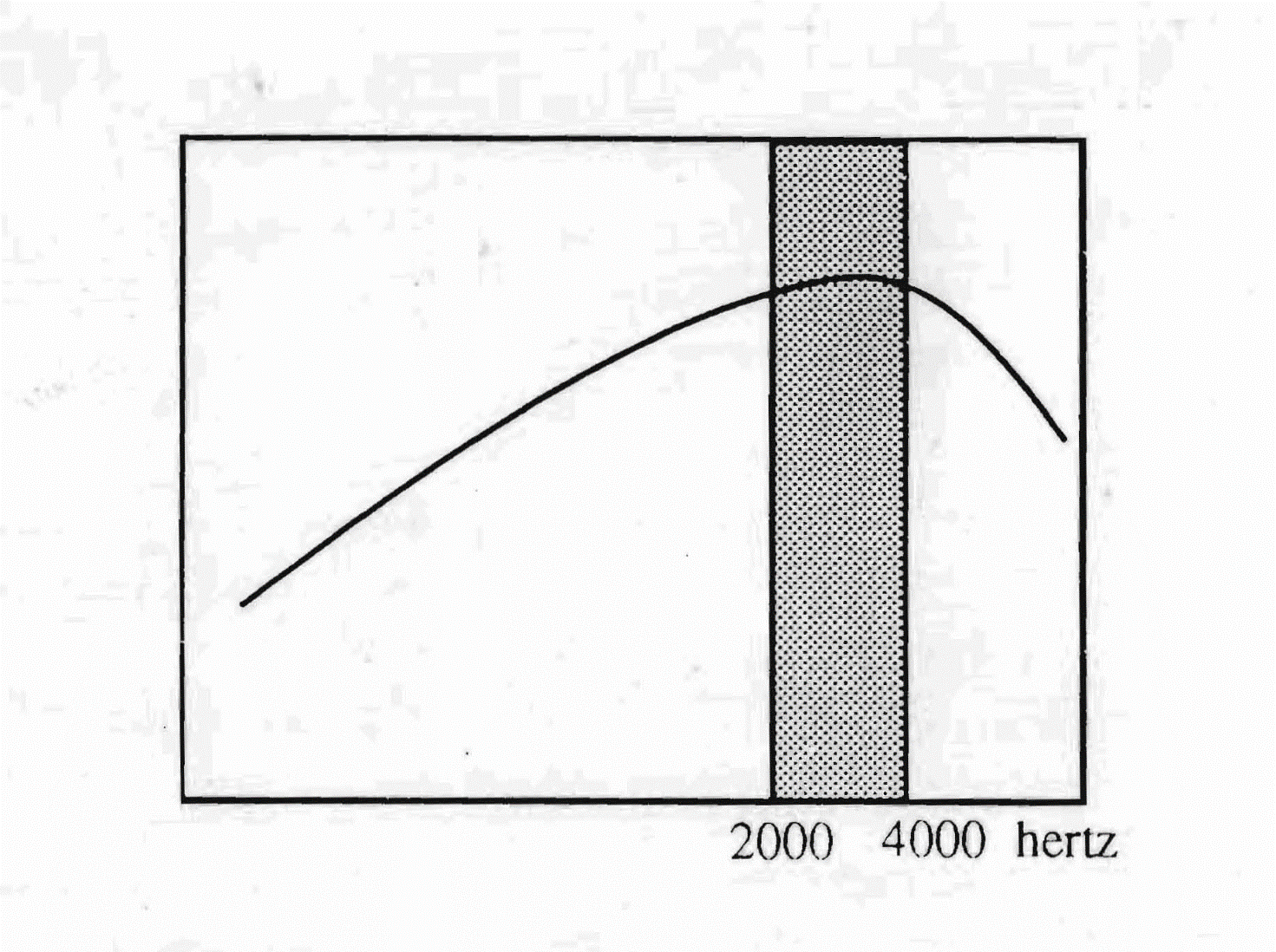
The passband of the Italian language covers a range of frequencies that goes from 2000
to 4000 Hz. The ascending trend of the envelope curve from the low sounds up to 3000
Hertz, and the subsequent slight inflection in the high sounds, give a musical type of listening